
These are the slides and notes of a talk we gave on April 29, in collaboration with Snowplow.


We are a Snowplow implementation partner and we work hand-in-hand with high-growth companies to help them scale their data capabilities We function as an interim data team and do a number of things for our clients.

We set up the right infrastructure for them (which is where our partnership with Snowplow comes in).
We deliver insights (the thing that matters most).
And we help them hire a data team (important because we believe these capabilities should ultimately be owned by the company, not outsourced).

But that’s enough about Tasman: let’s talk about data quality
This will be a shorter presentation so it’s by no means comprehensive–instead, I’ll highlight a few thoughts and observations made after having worked in this industry for a little while now.

The first question is: what do we mean by data quality and how do we measure it?
One definition I found online states the data quality can be assessed on whether it’s
- Accurate
- Relevant
- Complete
- Up to date
- Consistent.
I tend to agree that these are probably good criteria to keep in mind when assessing data quality, especially the criteria around accuracy and relevancy are broader than a narrow technical definition of quality. Moreover, data quality can and should ideally be assessed at every step along the way. But the final assessment, the one that matters the most, is when the business uses the data to make decisions.
Issues with data quality will hinder the business when making decisions — you can do everything right up until the last step, but if you make a mistake there, it doesn’t matter that everything done before that last step was right.

So why is this so hard?
It’s tempting to ignore issues, especially if they are not that big, or slightly fudge the report, or say “we’ll investigate and fix later”. We all know that issues often don’t get investigated let alone fixed, because we have to move on to the next deliverable or something else is being prioritsed.
The result is that these errors compound over time which, in turn makes it harder to find the problem. It’s a lot easier if you have the opportunity to start from scratch, but almost no one is truly able to do that–most people inherit an existing setup

The result?
Well, poor data quality leads to bad decisions, either by humans or by automated systems

And, even worse, poor data quality erodes trust in the data & data team. This is hard to recover from as a team.
Once trust is lost, it’s hard to gain it back without making drastic changes.

So what’s the solution?
Unfortunately, there is not that one magical fix we can deploy that solves all our problems. There is no easy solution to the problem of data quality that many companies face/
But what we know is that it is important to get data collection right as problems with data quality become harder, or even impossible, to solve when you are further down the pipeline.
And data quality requires that people, products and processes all care about it–if these three elements are not aligned, issues will inevitably arise!

People matter because you need a culture where data quality is something that is collectively cared about. Products also matter: they can make it easier or harder on people dealing with data quality issues. Processes are, of course, important too, as it ensures the data quality gets the necessary time and attention as part of the regular day to day operations.

But… even if we get everything right, there are still some inherent limitations and tradeoffs too, which we’ll discuss below.

Let’s go in a bit more detail!
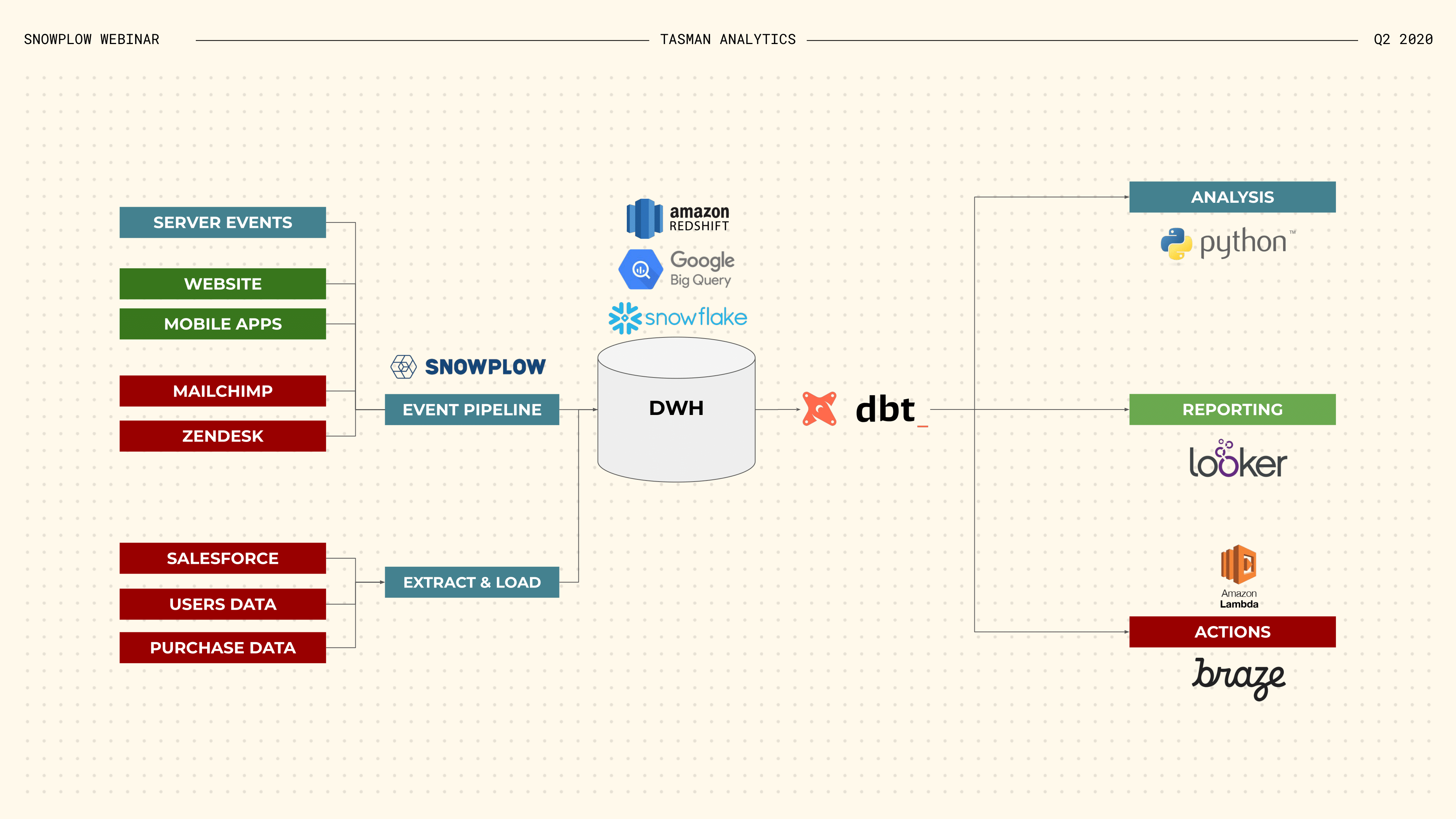
This diagram represents a simplified, but fairly representative, data stack for one of our clients. On the left are our data sources, which fall into 2 broad categories:
- On the bottom left is the extraction of data from other systems (think Salesforce, Google Ads, Facebook Ads, …)
- On the top left is the capturing of behavioural data from your website, apps, and other systems via an event data pipeline like Snowplow.
Data from all these different sources gets loaded into our SQL data warehouse, where we transform it, before using it across the business.
In the remainder of my presentation, I’ll go deeper into 2 elements of this stack:
- First, event data collection
- Then, data modeling & analysis.


There are a few things that make event data collection harder than some of the other types of data collection or extraction.
First of all, you only get one shot at collecting this data. You need to collect the event when the action is happening: if you fail to collect it or if the data you send is invalid, then you have lost your opportunity to capture this event. So if a release breaks a key set of events in your app, and you didn’t catch it before release, that data will forever be lost.
There is also not always a source of truth to compare the data against! You can compare some numbers, like total registrations or transactions, but that’s not possible with much of the other data you collect. Comparing against a different pipeline is not a solution either because it’s likely to show a different number but neither are necessarily true and it won’t get you closer to figuring out why the numbers are different.
There’s also no magic here: collecting structured data requires careful planning and execution. Features of a product will only get you so far. You need the right attitude in people and the right processes too.

So what can we do?
First is making sure that we collect the data in the first place. We get one shot at collecting this data, so if we don’t instrument the tracking then we lose our opportunity altogether.
One way to do it is to make tracking is an integral part of the product development. Once it has been released, things like regression testing can help ensure that the tracking doesn’t accidentally break in a future release–again relying on automated testing here.
One thing Snowplow does particularly well is transparent processing from the collector all the way to the data warehouse–the pipeline is not a black box so you can be sure that nothing goes wrong with the data while it’s being moved from one stage to the next.
There is structuring the data and validating it early and often. And there is extensive automated testing, both of the tracking and in the data warehouse.

That said, it’s also important to be aware of some inherent limitations to data collection. There are inherent limits on completeness — for example, there is the requirement to make tracking opt-in rather than opt-out. Ad blockers also hide a significant percentage of web traffic.
Therefore, if you only track on the web, this means you will not collect data from part of your visitor base.
There are also limitations on accuracy:
- Bots & spiders have been issue since the dawn of web analytics
- But current and future restrictions on things like cookies also reduce the accuracy of some of our reports
So, what to do? First of all, it’s important to be aware and honest about these limitations.If you do this, you can also look for alternative sources of data that don’t face these same limitations.
For example, a combination of client-side and server-side tracking lets you report on key KPI’s with full accuracy whilst also being able to build the kind of detailed behavioural profiles that can only be built with client-side data, even though you can only do so for the visitors that can be tracked.
If alternative sources of data are not available, then be careful to not report absolute numbers without context and instead focus more on the types of analyses that don’t require a complete dataset necessarily.

This brings me to the last part of my presentation: Data quality in data modeling & analysis.
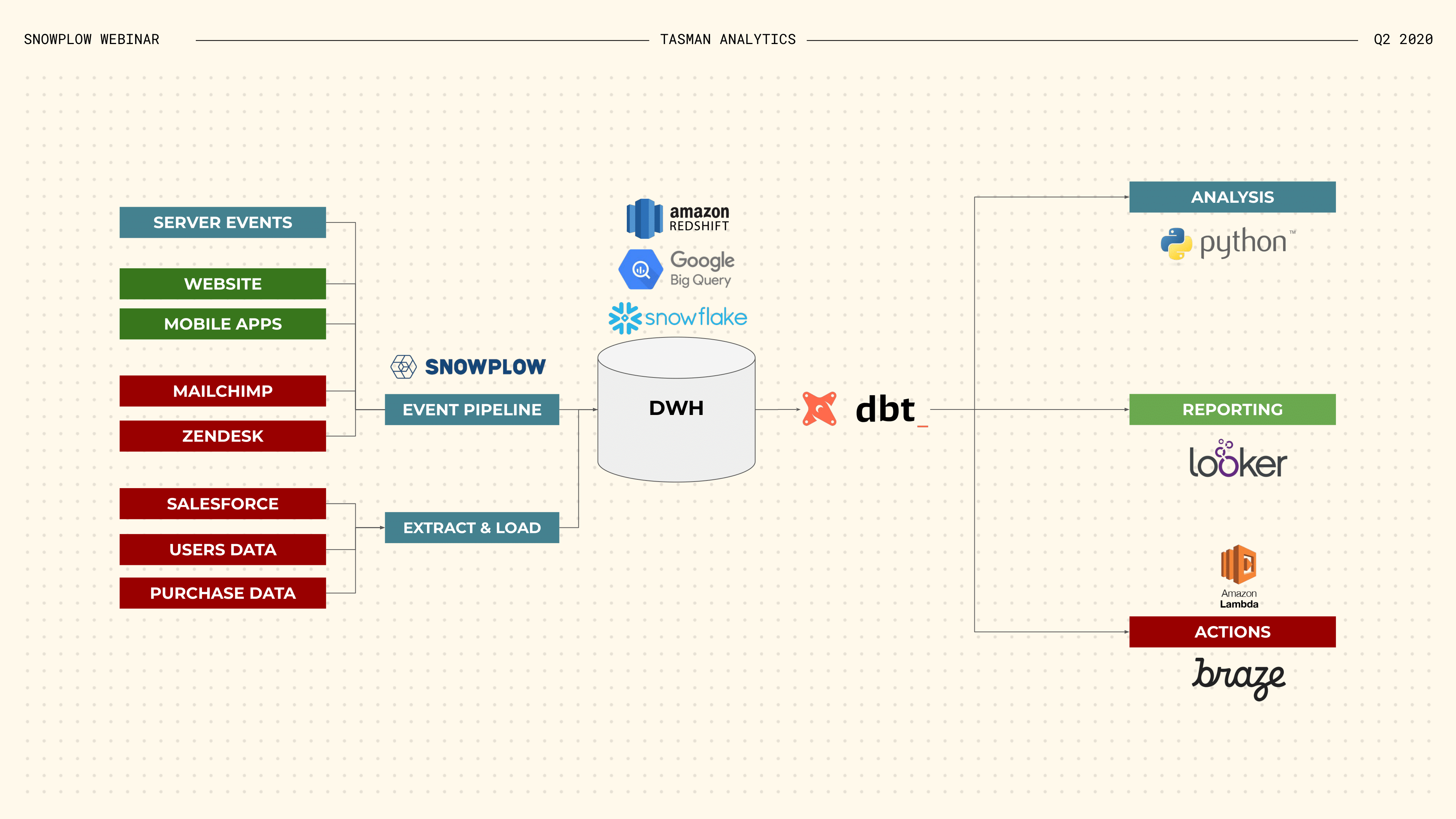
Let’s go back to this diagram for a minute. On the left, we collect and extract data from a large number of sources: our website, mobile apps, CRM and so on. This data is then loaded into our SQL data warehouse, or data lake, where we using it in a variety of ways.
Everything discussed so far is about ensuring that the data we load into our data warehouse is of good quality. This is of course crucial, for the reasons previously discussed:
- We may only get one shot at collecting this data
- And it is much more difficult and time consuming to fix data this far down the pipeline. But concerns about data quality don’t end when we load data into our data warehouse.
There is this second half to the diagram. Whereas in the previous paradigm, the order would have been Extract Transform Load, it now is Extract Load Transform.
The transform step now happens in the SQL data warehouse, where we integrate data from across the business and create new data sets that are designed for specific use cases by downstream consumers–whether they are data analysts, data scientists or business users.

We should therefore also care about data quality at the transform stage, as well as any stages that are even further downstream. Ultimately, data quality is assessed at the point where we use the data to inform decision making.
If we do everything right during collection but introduce mistakes during data modeling–i.e. in the transform step–the end result for the business is the same: it could lead to the wrong decisions and the business may lose trust in the data & data team, regardless of where the problem was introduced.
Unfortunately, this is where we see a lot of problems being introduced. There are a variety of factors that contribute to this:
- SQL data models often grow to become complex and hard-to-understand and are poorly documented
- Sometimes there is no explicit agreement on business definitions
- Or there’s pressure to get something out quickly
- And there has historically been a lack of tooling in this area–especially compared to what is available upstream in products like Snowplow–and it is tooling like this that turn things like testing from a manual process into an automated one.

So this brings me back to this slide. As was the case with event data collection, there is not going to be a single solution that solves all these problems. Instead, we have to look at people or culture, product or technology, and our processes to identify what we can do in each of these areas to help uphold data quality standards.

Even though this area has historically been underserved, things are getting better fast! Companies are already centralising their data. They should also centralise their data model so that there is a layer of modelled data that is well documented, well tested and, most importantly, consistent across the business.
In a hub and spoke model, individual teams can then build their own models & reports on top of this common foundation–following the best practices set by the central team. There is also the development of analytics engineering as its own field within data–distinct from data engineering, data analytics and data science.
Analytics engineers are responsible for SQL data modeling–integrating all the different sources of data and producing clean, well-structured data sets for the downstream consumers, which can be data analysts, data scientists, business users, or automated systems. And lastly, the development and adoption of open source products like dbt has made tooling that was previously only available to engineers available to anyone doing SQL data modeling.

I want to end with one caveat… and that is it’s fine to make certain tradeoffs.
Until now, we have spoken about data quality as a thing we should always aim to maximise
That is definitely true when we collect data: we want the source data in our data warehouse to be of as high a quality as it can be, for the reasons Yali and I have highlighted before
But I would argue that it’s fine to make certain tradeoffs further downstream–when we model and analyse the data
Take this quote from the VP of Data at Monzo:
We’re explicit about data accuracy requirements. We make a distinction between two different types of datasets. For many data-informed decisions, it’s fine when something is 98% correct and you’re optimising for speed. In other cases (like financial reporting, for example) data needs to be ‘bang-on’.
One of the criteria to assess data quality is accuracy, and sometimes it’s fine to make a conscious decision to sacrifice high accuracy in favour of speed when we model and analyse the data
Key here is that it’s a conscious decision we make, not an unintended consequence of the way we’re doing things, and that we retain the option to revisit our decision, spend the time and improve accuracy
This is, of course, only possible if we make sure we collect high quality data in the first place, without which we simply lose the option to produce accurate reports
