Find the other parts in this series here:
- Part 1: What we like about Snowflake (this post)
- Part 2: What we like about BigQuery
Pricing
Snowflake’s pricing is based on a consumption model, which charges based on the duration of queries/computation in flight i.e. the longer it takes your queries to run, the more costly it is.If we have large swaths of data to transform, but the time to process these only take up a small amount of time, then this works out better for us and the clients.
This isn’t all just about running at lower costs! If the business requires data in a timely manner, then you can configure production jobs to run with a larger virtual warehouse and have the development/testing jobs to operate on a smaller virtual warehouse - all of which allows us to run jobs in a flexible and scalable manner for our clients.
Pro Tips
⚠️ Set a timeout! If a query runs indefinitely then this will eat up your whole budget.
This is another good point to why we like Snowflake. We can cap our payment amount by prepurchasing credits, which other cloud providers rarely offer - some would give you a notification that you have reached the designated threshold, and it will be dependent on you to action.
⚠️ Going into technical ground here, Snowflake charges by the uptime of the warehouse that runs the query computation, with a minimum of 1 minute once a query starts running. By default, there is an auto-suspend setting at 5 seconds (can be extended up to 60 seconds). If you don’t batch your jobs together then you could end up with a bill that could have been worth much less.
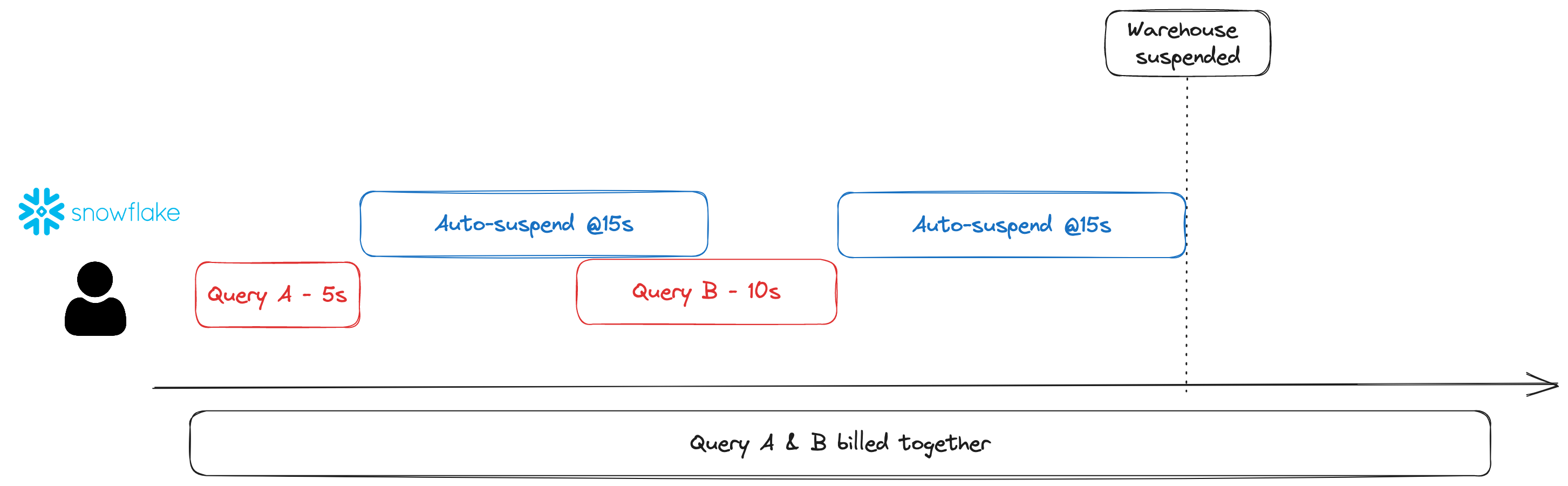
Snowflake Auto Suspend schematic
This is only the tip of the iceberg when it comes to optimising costs, expect there to be another post on this in much more detail.
Steamrolling nested data
Extracting semi-structured nested data (most commonly JSON) into a structured format for analytics reporting can be easier said than done. If your business deals with a lot of these data formats, then Snowflake makes it extremely simple to wrangle this type of data.
Other data warehouse tools will require a base understanding of json arrays/functions and the approach typically goes:
- Extract array from json
- Flatten/unnest array
- Extract value from flattened json object
- Cast to the relevant data type
This is fairly straightforward, but does require you to know what functions to use and how to combine these together to arrive at your final state of structured data.
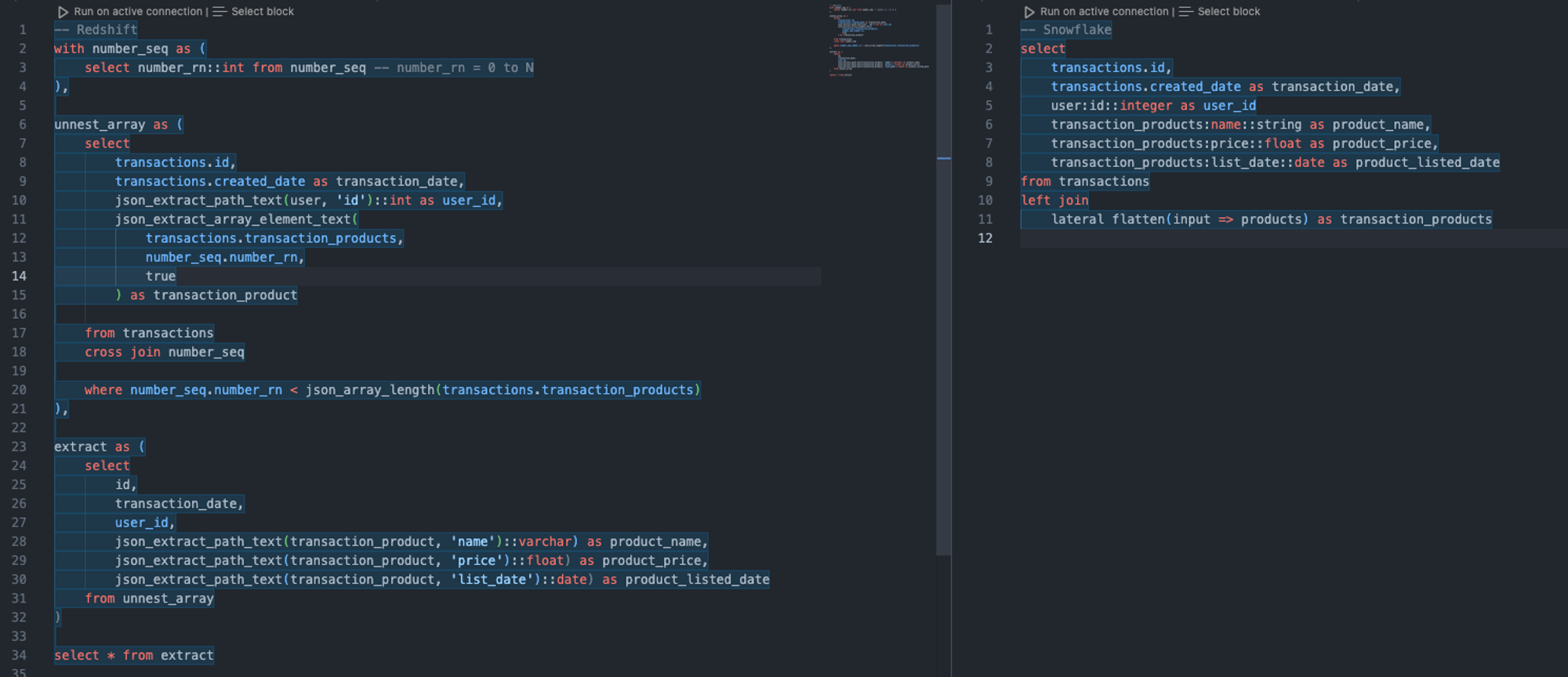
Redshift flattening versus Snowflake flattening
The above shows a comparison of how Snowflake differs in flattening nested objects to Redshift. Once you get the hang of it, there’s not much difference, but Snowflake is more intuitive in this case and offers a lower learning curve than the rest.
This is powerful as it means your team can start building queries and get to insight quicker without spending time learning the tool. From a query maintenance perspective, this definitely pays dividends in the future also.
Automatic optimisations
Snowflake helps you implement micro-partitions meaning you won’t have to dedicate any headspace into thinking how to configure your table partitions. Similar to the above, this reduces the time for a data/analytics engineer to optimise data tables for efficiency allowing them to focus their time on other value-driven initiatives.
Storage is automatically compressed with a compression algorithm, which helps with storage costs. Other optimisations include point-queries, query plan on the fly, caching to name a few, meaning your engineering resource won’t have to dedicate time in maintaining the data warehouse such as configuring number of clusters.
🎵 You can still have control over how your tables are partitioned if you deem Snowflake’s default configuration for micro-partitions as subpar according to your setup.
🎵 You can also improve query performance through clustering which sorts the data within the micro-partitions, helping with data retrieval and processing. However, only consider clustering certain tables, as tables with many DML operations (insert, update etc) will mean reclustering on a frequent basis which can be expensive and lead to diminishing returns.
Database security management
For certain businesses, they’ll want to restrict access to their data to certain functions e.g. the invoice team can have access to orders/invoice transaction data but they can’t have access to employee payroll data that the payroll team uses on an on-going basis.
Snowflake uses Role-based access control (RBAC) - a security model that is easy to understand which simplifies the management of who has access to what. A role is essentially a list of permissions (I can read this table, I can write to this table etc). Depending on the type of data your business handles, its sensitivity, and the teams or functions that require access to this data, you can define roles to address these factors.
We like this as it allows our team to quickly hit the ground running (and seamlessly) so we can start doing what we do best. This is also valuable for when we reach a point where we help our clients in building out their data teams and onboarding them in a similar manner to us.
Snowflake Query Profiler & Column-level Summary
These quality of life aspects of the tool make it simple for us to optimise any inefficient queries.
When things are taking forever to run, this allows us to find out where the current state of querying is at and address the issue. Whereas for other data warehouse tools, this may happen at the end of query runtime.
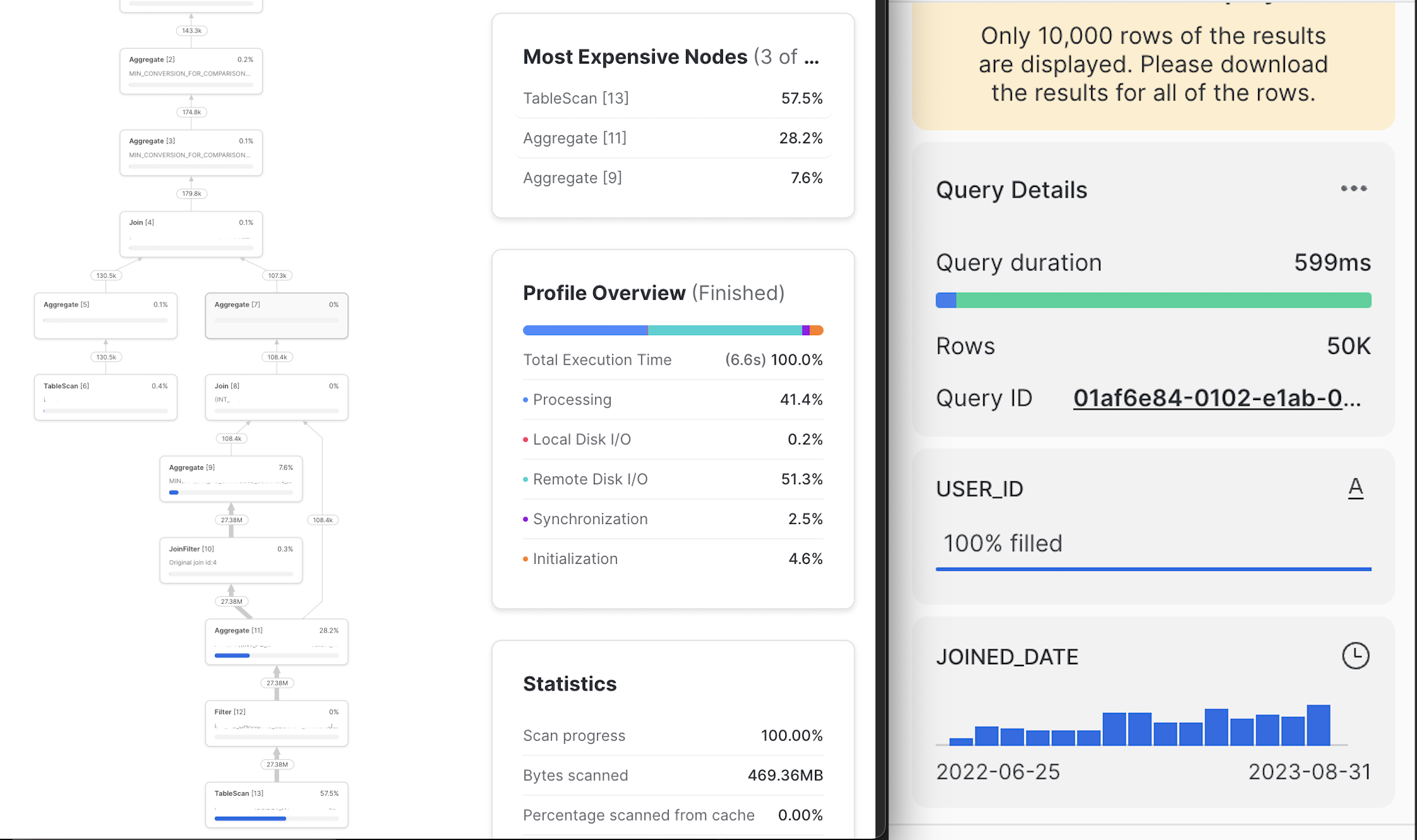 The Snowflake Query Profiler and the Column Summary
The Snowflake Query Profiler and the Column Summary
Time Travel functionality
Snowflake keeps snapshots of your tables for up to 1 day (90 days for Snowflake Enteprise), allowing users to query your data up to a certain point in time.
This is great for the occasions where you need to quickly rollback some changes that were accidentally deployed to production, or worse case when a table was truncated or completely removed from a security breach etc.
🎵 There are other providers that provide this time travel functionality for longer than 1 day e.g. BigQuery has 7 days. Having said this, 1 day is better than none and will likely save your business from some desperate fire fighting. These are also costs that your business don’t have to pay for which is great.
Snowflake isn’t perfect
The above points have mostly been the features that we have capitalised on, though there exists scenarios where utilising Snowflake won’t provide the client with the expected value and thus we’ll go about using a different tool.
Some scenarios that make Snowflake a bad contender:
❌ If the business requires a realtime solution. As mentioned above, Snowflake charges at the uptime of the warehouse, so if you are frequently running processing jobs, then it may be more sensible to opt for other tools that offer a non-PAYG model.
❌ If there is a business requirement to have their data remain on-prem. Industries such as healthcare or traditional finance require strict lockdown with their data. Whilst Snowflake is compliant in industry standards such as HITRUST, it may still fall short if businesses are required to adhere to more specific regulations or policies.
Still reviewing
These have been features of Snowflake since the beginning of its inception, and it is continuing to release new capabilities. Some are useful, and some not so useful which all boil down to what problems we’re trying to solve for the business. Nonetheless, it is a solid tool that will get you far in the data warehouse journey.
We hope you enjoyed this read!