Creating an Event Stream using Rudderstack Transformations

Event data is the lifeblood of any modern analytics stack — and how you load events into your data warehouse can have a huge impact on the data modelling complexity and on-going maintenance required.
There are two main flavours of warehouse event schemas – the table-per-event and the event stream.
These can be characterised as follows:
- Table-per-event: Events are stored in their own tables with their own schemas. JSON payloads are flattened, and event schema evolution is typically managed by adding new columns for each new property that is captured. Often tables are organised into a schema or dataset per source to provide additional structure.
- Event stream: Events are all loaded into a single table and typically semi-structured data formats are used to store properties. As a result, the table schema is kept separate from the event schema, requiring fewer mutations as tracking evolves.
The debate between these two strategies could be likened to the normalisation vs denormalisation or Kimball vs Inmon vs OBT. There are strong opinions that change with every technological iteration but, in reality, the optimal approach depends on your specific circumstances and constraints.
Tracking and data architecture
A traditional CDP architecture means that routing of data to downstream systems is managed by the platform, and the data warehouse plays a less critical role. In composable and warehouse native CDP architectures, the data warehouse becomes the central data repository, and data is loaded into and sourced from the warehouse. The warehouse schema in this architecture can have a big impact on the amount of work required to maintain and support data models as tracking evolves.
Data Use Cases
The usage of the data in the warehouse for analytics and insights purposes is an important consideration. The priority might be a single-customer-view, or comprehensive product analytics, where events from different sources are used to build a complete picture of user behaviour. Alternatively, data sources may need to be kept isolated from each other – perhaps a central tracking solution providing data for subsidiary companies that will own their own data.
Data Volumes
At a certain point, volumes of tracked data may start to create optimisation challenges. In today’s modern columnar data warehouses, optimisation is often less of a priority, however at billions or trillions of events scale, every single operation completed on that data will have a noticeable cost and performance impact.
When to load data using a table-per-event schema?
There are a few reasons you might elect for a table-per-event schema:
- A table per event schema is a more rigid approach with some data modelling essentially baked in. Because each event type has its own table, tables can sometimes be more manageable and performant, and potentially less expensive to query if you have large-scale event volumes, and are evaluating events in isolation.
- Moreover, it’s easier to understand a table-per-event schema at a high level. You can look at the schema and know what’s available because it’s apparent exactly which traits are associated with each event. This makes it easier for new team members or folks who are unfamiliar with the dataset to come in and use the data, particularly where there is less expertise handling semi-structured data as this is a key requirement of a single-event-table schema.
- Table-per-event schemas also deliver a major advantage in situations where data needs to be kept separate per source for compliance/legal reasons, or organisational structure reasons.
When to load data using an event stream schema?
In our experience, loading data as event streams is preferable in nearly all situations for one really clear reason – in a columnar data warehouse, it’s much easier and more efficient, at both small and massive scale, to take an event stream and model it as a table-per-event schema using simple filters, than it is to take a table-as-event schema and create an event stream. Thus, event streams grant significantly more flexibility and reduced complexity, allowing Analytics Engineering teams to more quickly construct models that unlock the value of the data.
Furthermore, while semi-structured data does have a learning curve, leveraging semi-structured data for event properties is magnitudes more robust, allowing tracking to evolve with the business requirements without it causing havoc across the data models. Data Analysis teams can even extract the properties directly at report time, reducing the maintenance load on Engineering teams drastically.
Answering business questions from events using SQL is also a lot easier with event streams. For example, creating a checkout funnel model for an e-commerce site for the last 30 days. This can be done with a fairly simple query, using no joins, only filters on columns that are often partitioned, and this can be made incremental with just 1 additional where clause (in dbt that is).
Some feel so passionately about the benefits of event streams, that they propose modelling all business data this way. See ‘Activity Schema’. In their 2.0 update, they also introduced using semi-structured objects to capture activity features (a.k.a event properties) too.
How to load data into Rudderstack as an event stream?
Rudderstack, one of our favourite warehouse-native CDPs, elects for a table-per-event schema, but by leveraging Rudderstack Transformations, it’s possible to load data as an event stream.
Step 1: Namespace
By default, the Rudderstack warehouse loader creates a ‘namespace’ per source ( namespace here being a generic term for ‘dataset’ or ‘schema’ that is non-DWH specific). The first small change is to set the namespace to be a fixed string (i.e. events_prod ) in the warehouse destination configuration settings. This ensures that the same schema is targeted, independent of the data source. After this change, we still have a table per event, but it’s in the same schema. And bonus, the identifies, users, tracks and pages standard tables are combined for all sources.
Step 2: Loading all events into a single table
The second change we need to make is to trick the loader into putting all of the individual event tables into a single table – this is the first step of the transformation. We achieve this by taking the name of the event (i.e. product_viewed ) and setting this to be a property called eventName (or similar) – this allows us to identify the original event. Once this is stored, we update the name of the event to be a fixed value – such as event. Rudderstack will then load all of the events into a table with the same name as the fixed value – in this case `event`.
Step 3: Loading properties as JSON
The final change we need to make is to capture the properties as JSON objects. We do this by leveraging Rudderstack’s JSON Column Support. This allows you to tell the loader which columns to not flatten, and load directly as semi-structured data. The catch here is that you can only do that to attributes within the properties object of the payload. We can get around this by using the transformation to dump everything we want to load (could be just the properties, but it’s a good idea to capture the context and integrations this way too) into the properties object.
const propertyBundle = {
"eventName": event.event,
"context":event.context,
"properties":event.properties,
"integrations":event.integrations
};
delete event.context;
delete event.integrations;
event['properties'] = propertyBundle;
event.event = 'event';All we then need to do is to set our JSON columns in the DW config to be:
track.properties.properties,
track.properties.context,
track.properties.integrations
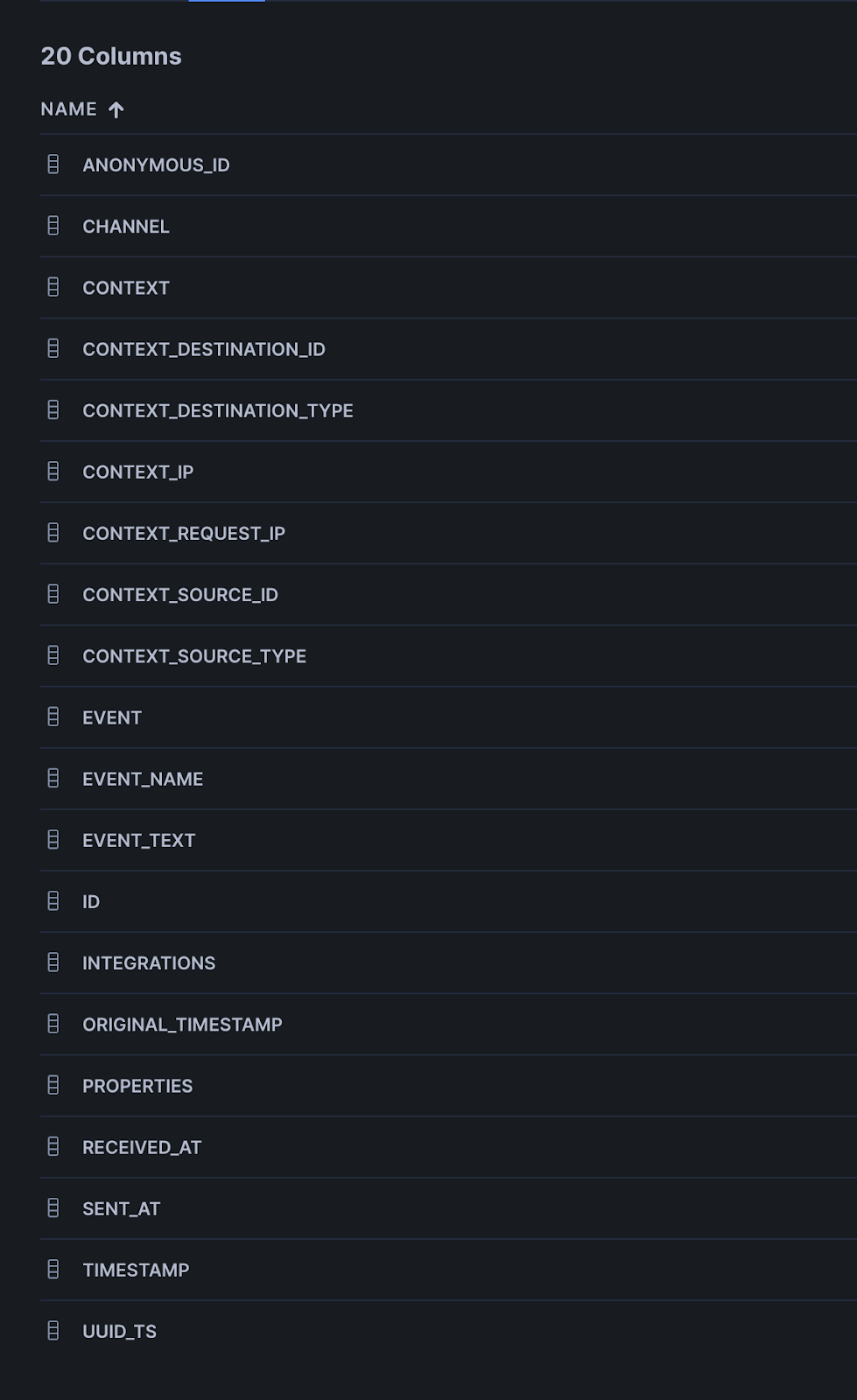
Step 4: Final Schema
The final schema will be significantly smaller than the standard Rudderstack warehouse schema due to use of the JSON columns. Unfortunately, it’s not possible to capture all context properties in the context object column – this is because these are added by the loader after the transformation has been applied, but these should remain fairly consistent.
Extracting properties from the properties object is as straightforward using dot notation (Snowflake SQL, but easily adaptable to other platforms).
select
properties.property_name::string as custom_property,
context.property_name::string as context_property
from
rudderstack_db.events_prod.eventThe beauty of this approach is that if a property isn’t available, it will not error but return a null. Similarly if a new property is added, this can be extracted without needing to change upstream models – and depending on the BI tool, can even be extracted at query time!
Restrictions with this approach
As this is a workaround, there are a couple of restrictions to be aware of:
- Page, identify and group calls are not able to be included in the event stream as these are handled differently. One way around this, is to use track calls for pages instead.
- As previously mentioned, columns added after transformation (e.g.
context_destination_typeandcontext_destination_id) are not able to be included in the main context JSON object.
Appendix
Original Payload
{
"anonymousId": "testID",
"channel": "web",
"context": {
...,
"traits": {
"user_company": "Tasman",
"user_email": "tom+skipform@hubspot.com",
"user_first_name": "Tom",
"user_job_title": "Chief Form Tester",
"user_last_name": "Shelley"
},
"userAgent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36"
},
"event": "case_study_viewed",
"integrations": {
"All": true
},
"messageId": "b0782ad5-2588-4143-b5f3-222536cdb319",
"originalTimestamp": "2024-08-12T11:51:22.152Z",
"properties": {
"case_study_title": "Kaia Health"
},
"receivedAt": "2024-08-12T11:51:22.379Z",
"request_ip": "86.24.250.48",
"rudderId": "48c7f79c-fd6d-4e8c-8131-b15a82697fee",
"sentAt": "2024-08-12T11:51:22.152Z",
"type": "track",
"userId": ""
}
Transformed Payload
{
"anonymousId": "testID",
"channel": "web",
"event": "case_study_viewed",
"messageId": "b0782ad5-2588-4143-b5f3-222536cdb319",
"originalTimestamp": "2024-08-12T11:51:22.152Z",
"properties": {
"context": {
...,
"traits": {
"user_company": "Tasman",
"user_email": "tom+skipform@hubspot.com",
"user_first_name": "Tom",
"user_job_title": "Chief Form Tester",
"user_last_name": "Shelley"
},
"userAgent": "Mozilla/5.0..."
},
"integrations": {
"All": true
},
"properties": {
"case_study_title": "Kaia Health"
}
},
"receivedAt": "2024-08-12T11:51:22.379Z",
"request_ip": "86.24.250.48",
"rudderId": "48c7f79c-fd6d-4e8c-8131-b15a82697fee",
"sentAt": "2024-08-12T11:51:22.152Z",
"type": "track",
"userId": ""
}Final Transformation Function
export function postProcessEvents(events, metadata) {
const postProcessedEvents = [];
events.forEach(event => {
//SNOWFLAKE DESTINATION ONLY - Create an event stream
if (metadata(event).destinationType == 'SNOWFLAKE'){
const propertyBundle = {
"eventName": event.event,
"context":event.context,
"properties":event.properties,
"integrations":event.integrations
};
delete event.context;
delete event.integrations;
event['properties'] = propertyBundle;
event.event = 'event';
}
postProcessedEvents.push(event);
});
return postProcessedEvents;
};