A Series A startup with 15k USD per month in marketing spend doesn’t need a 5,000 USD per month data warehouse. They need to know which campaigns are working, and which ones aren’t.
Yet the default advice remains: adopt the Modern Data Stack. Get dbt for transformations, Snowflake for warehousing, or maybe Databricks if you’re feeling ambitious about AI. Future-proof yourself. Take the time to build properly.
But small companies need to act fast. While you’re configuring role-based access controls and debugging Airflow DAGs, your competitor just figured out their best-performing channel and doubled down.
The goal remains: centralised, cloud-stored data with a single source of truth. That’s non-negotiable. The question is whether you need enterprise-grade infrastructure to get there right now, or whether leaner tools deliver the same outcome faster and cheaper during the phase that matters most.
So whenever I get that question, the razor I apply is whether this gets me to actionable insight faster?
The Modern Data Stack: Promise Versus Reality
The pitch is seductive. dbt gives you version-controlled, tested transformations. Snowflake separates storage and compute. Databricks handles ML workloads at scale. Together, they form an enterprise-grade foundation.
For companies processing terabytes daily or operating under strict regulatory requirements, these tools earn their keep. McKinsey’s research on data-driven organisations confirms that mature data infrastructure correlates with better decision-making—but maturity isn’t the same as complexity.
Most startups aren’t processing terabytes. Not yet.
We’ve built data platforms for over 50 high-growth companies at Tasman. The pattern repeats: early-stage teams adopt MDS tools because they look serious, then spend months servicing infrastructure instead of serving stakeholders. A founder who should be reviewing cohort retention is debugging a dbt macro. An analyst who should be investigating why CAC spiked last week is waiting for Snowflake credentials.
Red flags that your stack is overkill:
- Data volumes under 100GB—this comfortably fits on a laptop
- No daily ML training jobs requiring distributed compute
- No dedicated data engineer to manage the infrastructure
- Monthly compute bills that exceed your analytics headcount cost
At this scale, the full Modern Data Stack doesn’t accelerate insight.
A Lean Data Stack Still Means Centralised Data
Something shifted in the past two years. You can now build a proper, centralised data platform—single source of truth, version-controlled transformations, governed access—without the enterprise price tag.
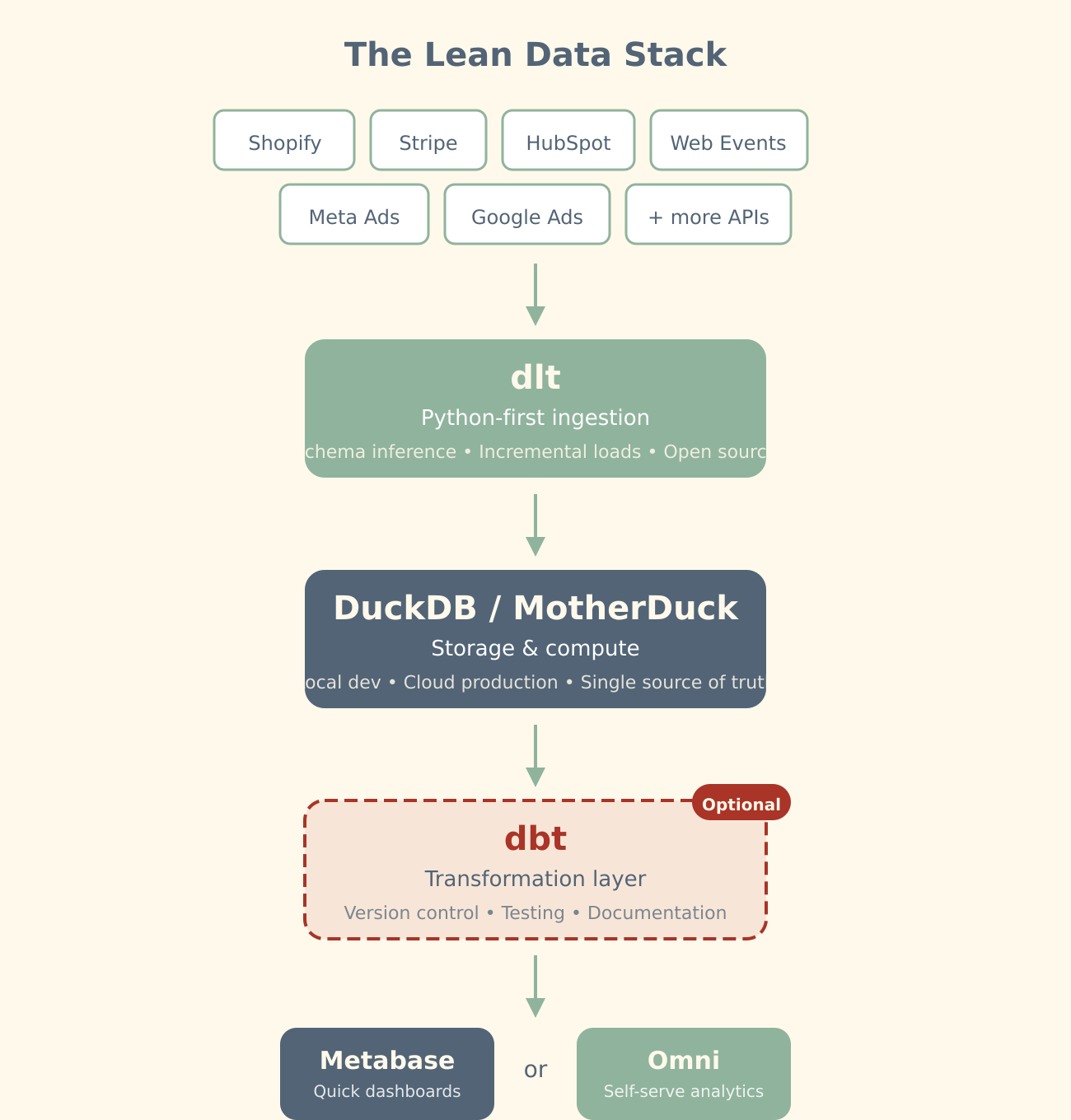
dlt handles API ingestion with schema inference built in. DuckDB runs analytical queries faster than most cloud warehouses. MotherDuck extends that to collaborative, cloud-hosted infrastructure. What used to require a data engineer, a week, and three vendor contracts now takes a founder and a weekend.
We’ve written previously about lean data stack principles—favouring managed services, reducing operational burden, unlocking higher-value work earlier. This post goes further: for pre-product-market-fit startups, even that lean stack may be more than you need. dlt and MotherDuck represent the next step down in complexity without sacrificing the centralised, governed data you’ll eventually require.
The engineering problem—getting data centralised and queryable—is increasingly commoditised. AI tooling accelerates the mechanical work.
What remains unsolved? Knowing what to look for.
AI can write your SQL. It cannot attend your board meeting or know that the attribution model flattering your paid social spend ignores a three-week consideration window. The insight layer—understanding which metrics drive decisions, which analysis changes behaviour—that’s where experienced humans earn their keep.
A lean data stack gets you to that conversation faster by removing the infrastructure overhead.
The Lean Data Stack That Fits
Here’s what a genuinely lean data platform looks like in 2025—still centralised, still governed, dramatically simpler.
Data Ingestion with dlt
dlt is a Python library for extracting data from APIs and SaaS tools. No managed service fees. You write a Python script; it handles schema inference, incremental loading, and data typing automatically.
Fivetran charges by monthly active rows, quickly reaching hundreds per month for modest volumes. dlt is open-source. The 80 per cent cost reduction is real, and you retain full control of your pipeline logic.
The trade-off is clear: Fivetran requires zero code and handles maintenance automatically. dlt requires Python competence but gives you complete flexibility. For a technical founder or a startup with any engineering capacity, dlt wins on economics. For teams with no technical resource at all, managed ingestion remains the right choice—we still recommend Fivetran or Airbyte for those cases.
Storage and Compute: DuckDB and MotherDuck
DuckDB is an in-process analytical database. No server. No connection overhead. Query 50GB of parquet files on a laptop in seconds.
For production, MotherDuck extends DuckDB to the cloud—same query engine, serverless execution, proper access controls. You get a centralised warehouse without the Snowflake bill. Their published benchmarks show 70 per cent cost reduction with comparable or better query performance.
The combination covers the full journey: prototype locally, scale to shared cloud infrastructure, never rewrite your queries.
Transformation Layer: dbt (Optional)
dbt remains excellent for version-controlled transformations. The difference: you’re running it against MotherDuck at a fraction of the compute cost, not paying Snowflake rates for every development query.
For simpler needs, DuckDB’s SQL capabilities often suffice without the additional layer. When you do adopt dbt, proper development practices matter more than the underlying warehouse.
BI Layer: Metabase or Omni
For quick operational dashboards, Metabase remains hard to beat. Open-source, deploys in minutes, no licence fees. Your marketing team can have campaign performance visibility by end of day—good enough for 80 per cent of early-stage reporting needs.
When you outgrow static dashboards, Omni offers proper self-serve analytics. A shared semantic layer means analysts define metrics once; business users explore freely. AI-native querying lets stakeholders ask questions in plain English. The investment makes sense once your team generates more questions than analysts can field.
A Lean Data Stack in Practice
Consider a Series A e-commerce company. Monthly marketing spend of €25K across paid social, Google Ads, and influencer partnerships. A founding team of twelve, no dedicated data hire. They need to understand which channels drive actual purchases—not just clicks—before their next board meeting in six weeks.
The traditional path: procure Snowflake, negotiate a Fivetran contract, hire a contractor to set up dbt, spend four weeks on infrastructure before writing the first query that matters.
The lean path: a founder spends Saturday writing dlt scripts to pull from Shopify, Meta Ads, and Google Ads. Data lands in MotherDuck. By Monday, they’re querying order attribution. By Wednesday, there’s a Metabase dashboard the whole team can access. Total cost: nearly nothing. Time to first insight: days, not months.
Six weeks later, they walk into the board meeting knowing exactly which channel delivers the best CAC:LTV ratio. They haven’t future-proofed for a scale they may never reach. They’ve answered the question that matters now.
This mirrors what we saw with On Deck, who had scaled rapidly using over 400 SaaS tools before realising they needed centralised data. The lesson: you need a single source of truth, but the path there doesn’t require enterprise tooling from day one.
Why Data Modelling Is Harder Than It Looks
Tools make writing models easy. Knowing what to model—that’s the craft. dbt’s own best practices documentation runs thousands of words on modelling structure, and even then, the hard part isn’t technical.
Why Business Logic Breaks Data Models
When does a “customer” become a customer? First purchase? Account creation? Signed contract? Every business defines this differently, and getting it wrong cascades through every downstream metric.
We’ve seen companies operate for years with two competing definitions embedded in different dashboards. The executive team quotes one number; finance quotes another. Both defensible. Neither documented.
Temporal Data Modelling Pitfalls
Point-in-time accuracy versus current state. Slowly changing dimensions. Timezone mismatches between your product and payment processor. Most modelling bugs stem from temporal assumptions that seemed obvious but weren’t.
Choosing the Right Data Grain
Model at the wrong grain and you’ll rebuild everything in six months. Too granular and queries crawl. Too aggregated and you lose flexibility for the next question. The right grain depends on questions you haven’t been asked yet—experience helps here.
Why AI Doesn’t Solve Data Modelling Yet
LLMs can write the SQL. They cannot know that “revenue” in your business includes three contract types with different recognition rules, or that the CEO’s definition of “active user” changed after last quarter’s board meeting.
Modelling encodes business logic. That logic lives in people’s heads, in Slack threads, in contradictory spreadsheets. Extracting it requires conversations and the pattern recognition that comes from seeing similar businesses make similar mistakes.
The temptation to vibe-code your data pipelines is real—AI makes it easy to generate plausible-looking models quickly. But plausible isn’t the same as correct. The shortcuts that feel efficient in week one become the debugging sessions that consume your weekends after a few months.
Why Data Infrastructure Isn’t the Hard Part
The Modern Data Stack discourse obsesses over infrastructure. It largely ignores the actual goal: insight that drives better decisions.
The real bottleneck is knowing:
- Which customer cohorts matter for your business model
- What “good” looks like for your CAC:LTV ratio at your stage
- Whether your attribution model reflects reality or flatters the best-tracked channel
- Which dashboard will change behaviour versus becoming shelfware
Tools like Omni let anyone query data conversationally. Powerful—and dangerous. Easy querying without contextual understanding produces confident nonsense. A stakeholder can now get a wrong answer faster and with more conviction than ever before.
This is where experienced analysts earn their keep. Not in writing SQL. In translating business strategy into data questions that matter, and recognising when the numbers are telling you something important versus something misleading.
A lean data stack frees budget and attention for this work. The expensive stack consumes both, leaving you with sophisticated infrastructure and no one to interpret what it’s telling you.
When the Full Modern Data Stack Makes Sense
To be clear: Snowflake, dbt, and the broader MDS ecosystem represent the best long-term architecture for most growing companies. The tooling is mature, the talent pool is deep, and the patterns are well-documented. When you reach the right scale, you should migrate.
The question is timing.
The full MDS makes sense when:
- Data volumes genuinely require distributed compute. Once you’re processing hundreds of gigabytes daily, MotherDuck’s economics become less compelling and Snowflake’s separation of storage and compute starts earning its keep.
- You have dedicated data engineering capacity. dbt, Airflow, and the surrounding ecosystem reward investment. A full-time data engineer can maintain these systems productively. A founder squeezing it in between customer calls cannot.
- Regulatory or compliance requirements demand enterprise governance. SOC 2, GDPR data residency requirements, complex access controls across multiple teams—these are legitimate reasons to adopt enterprise tooling earlier.
- You’ve found product-market fit. This is the crucial one. Before product-market fit, your priority is learning fast: which customers matter, which features drive retention, which channels scale. You need answers in days, not weeks. Infrastructure that slows iteration is actively harmful.
After product-market fit, your priorities shift. You’re scaling what works rather than discovering what works. Reliability, governance, and long-term maintainability matter more. The full MDS serves this phase well.
For a detailed breakdown of which tools fit which growth stage, see our Founders Guide to an AI-Native Data Stack in 2025. It covers the full journey from pre-revenue through scale-up, with specific recommendations at each phase.
The mistake is adopting post-product-market-fit infrastructure during the search phase. You’re optimising for a future that isn’t guaranteed while handicapping the iteration speed that determines whether that future arrives at all.
Start lean. Graduate when graduation makes sense.
Building a Lean Data Stack: The Path Forward
For startups still searching for product-market fit, the full Modern Data Stack is premature optimisation. Leaner tools deliver the same outcome—centralised data, single source of truth, governed access—faster and cheaper, preserving your runway and your attention for the work that actually matters.
The path:
- Audit your data volume. Most startups’ data fits comfortably on a laptop.
- Pilot dlt and DuckDB locally. One afternoon. No vendor calls.
- Scale to MotherDuck for production. Same queries, cloud execution, shared access.
- Start with Metabase for dashboards. Graduate to Omni when self-serve becomes critical.
- Invest the savings in people who understand your business. The modelling expertise and analytical judgement that turns data into decisions.
- Migrate to the full MDS when you’ve earned the complexity. Post-product-market fit, with dedicated data engineering capacity, and genuine scale requirements.
Your data infrastructure should be smaller than your team, simpler than your product, and entirely in service of the decisions you need to make. Build for the stage you’re at, not the stage you hope to reach.